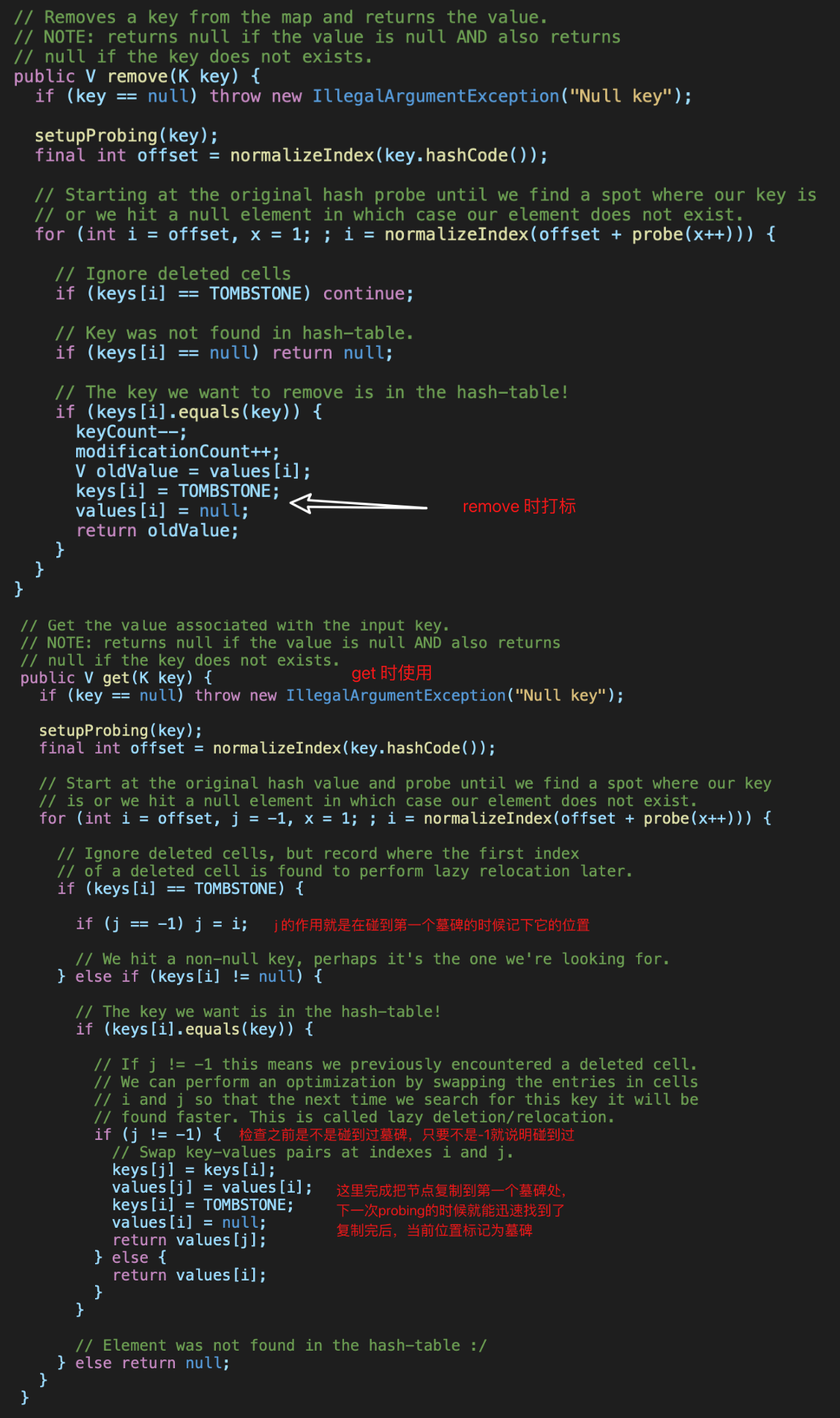
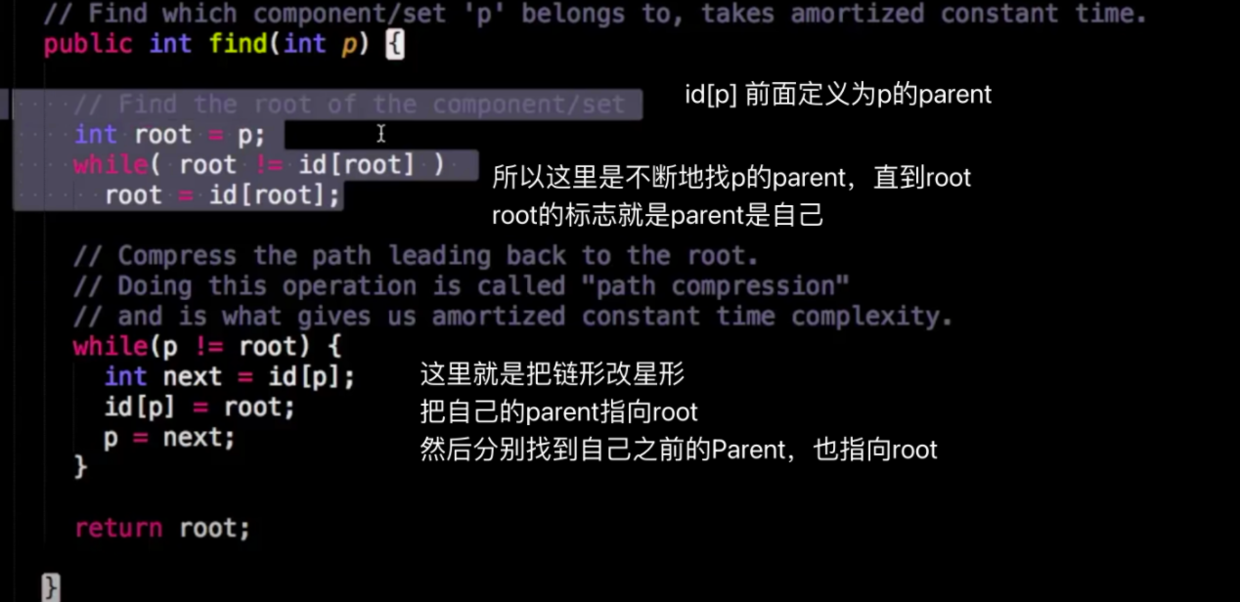
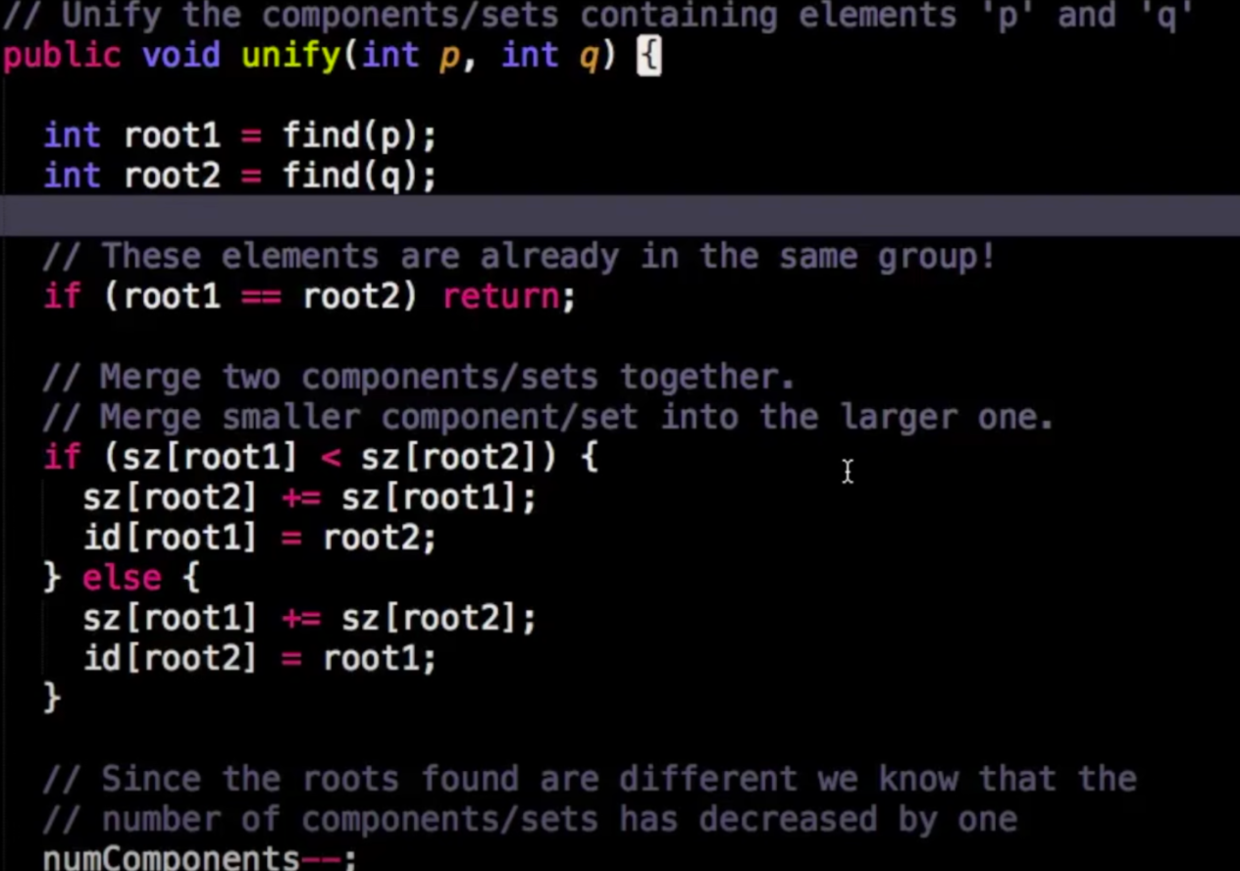
《Programming iOS 14: Dive Deep into Views, View Controllers, and Frameworks》第25章
Thread
Thread在开发过程中基本上线程是隐形的,你感知不到,因为大多数情况下,程序只(需要)跑在主线程上,这是没有问题的:
- 你的代码事实上执行得非常快,你感知不到
- 响应逻辑过程锁死UI,是安全的操作
原生的后台线程:
- 动画:The Core Animation framework is running the animation and updating the presentation layer on a background thread.
- 网络:A web view’s fetching and loading of its content is asynchronous
- 影音:Sounds are played asynchronously. Loading, preparation, and playing of movies happens asynchronously.
- 存盘:UIDocument saves and reads on a background thread.
但所有的complete functions / delegations / notification 都是在主线程被调用的
多线程的问题
- 调用时机/顺序不可控,次数也不可控,随时可能被执行
- 数据的线程安全,不得不借助“锁”的机制来保证(race condition)
- a lock is an
invitation to forget to use the lock, or to forget to remove the lock after you’ve set it.
- The lifetime of a thread is independent of the lifetimes of other objects in your app.
- 一个对象的退出不能保证有后台线程将来会调用它 -> 闪退或Zombie
- Hard to debug.
XCode对debug的支持:
- Debug navigator
NSLog / os_log / Logger outputs- Instruments > Time Profiler
- Thread Sanitizer, Main Thread Checker (项目配置 > Diagnostics)
执行后台线程的方法:
Manual Threading
performSelector(inBackground:with:)
- 只能传一个参数,多个参数要打包
- 手动管理内存 -> wrap every thing in an autorelease pool
func drawThatPuppy () {
self.makeBitmapContext(size:self.bounds.size)
let center = self.bounds.center
// 这里打包参数为一个字典
let d : [AnyHashable:Any] =
["center":center, "bounds":self.bounds, "zoom":CGFloat(1)]
self.performSelector(inBackground: #selector(reallyDraw), with: d)
}
// trampoline, background thread entry point
@objc func reallyDraw(_ d: [AnyHashable:Any]) {
// 手动控制内存
autoreleasepool {
self.draw(center: d["center"] as! CGPoint,
bounds: d["bounds"] as! CGRect,
zoom: d["zoom"] as! CGFloat)
// 手动回调主线程
self.performSelector(onMainThread: #selector(allDone), with: nil,
waitUntilDone: false)
}
// called on main thread! background thread exit point
@objc func allDone() {
self.setNeedsDisplay()
}
即便如此,还是没有解决不同线程使用同一个实例变量(如bitmapContext)造成程序非常脆弱的问题,得进一步使用lock等机制。
Operation
- 将
thread封装成task,表示成Operation 通过 OperationQueue来操作。
- 回调机制变成了通知机制(或
KVO)
let queue : OperationQueue = {
let q = OperationQueue()
// ... further configurations can go here ...
return q
}()
func drawThatPuppy () {
let center = self.bounds.center
// 也可以用 BlcokOperation
// 来执行你的耗时操作
let op = MyMandelbrotOperation(
center: center, bounds: self.bounds, zoom: 1)
// 通知/回调
NotificationCenter.default.addObserver(self,
selector: #selector(operationFinished),
name: MyMandelbrotOperation.mandelOpFinished, object: op)
// 结合起来
self.queue.addOperation(op)
}
而一个Operation子类包含两个部分:
- A designated initializer
- A main method
- 耗程序真正执行的地方,OperationQueue执行到这个Operation的时候就会被自动执行
class MyMandelbrotOperation: Operation {
static let mandelOpFinished = Notification.Name("mandelOpFinished")
// 1. params -> arguments
private let center : CGPoint
private let bounds : CGRect
private let zoom : CGFloat
private(set) var bitmapContext : CGContext! = nil // 封装成了类属性,不再线程共享
init(center c:CGPoint, bounds b:CGRect, zoom z:CGFloat) {
self.center = c
self.bounds = b
self.zoom = z
super.init()
}
// 1.1 logic
let MANDELBROT_STEPS = 100
func makeBitmapContext(size:CGSize) {
// ... same as before
}
func draw(center:CGPoint, bounds:CGRect, zoom:CGFloat) {
// ... same as before
}
// 2. main
override func main() {
// 首先要检查isCancelled
guard !self.isCancelled else {return}
self.makeBitmapContext(size: self.bounds.size)
self.draw(center: self.center, bounds: self.bounds, zoom: self.zoom)
if !self.isCancelled {
// 完成通知,也可以用KVO机制
// 主线程接收到后要立即处理,因为OpearationQueue将会立即释放这个Operation
// 此外,接收通知可能也不在主线程,-> GCD
NotificationCenter.default.post(
name: MyMandelbrotOperation.mandelOpFinished, object: self)
}
}
}
// 3. observer
// 就是前面在主线程里注册监听消息的方法
// warning! called on background thread
@objc func operationFinished(_ n:Notification) {
if let op = n.object as? MyMandelbrotOperation {
// 1. 主线程(GCD)
DispatchQueue.main.async {
// 2. 移除通知监听
NotificationCenter.default.removeObserver(self,
name: MyMandelbrotOperation.mandelOpFinished, object: op)
self.bitmapContext = op.bitmapContext // 传回这个之前是线程共享的变量
self.setNeedsDisplay()
}
}
}
注意bitmapContext这个之前主线程设置,然后后台线程共享的变量,现在由Operation这个类自己持有,结束时才赋值回主线程。
此外,还能限制并发数量:
let q = OperationQueue()
q.maxConcurrentOperationCount = 1
This turns the OperationQueue into a serial queue.
最后,解决最后一个问题,即你的调用者都没了,比如ViewController没了,调用者没了,后台任务也理应取消(下载、存盘类不需要UI交互的除外)
deinit{
self.queue.cancelAllOperations()
}
至此,前面提到的一些多线程会带来的问题如调用时机和数量不可控,跨线程数据安全,以及生命周期等问题,Operation都完美解决并封装了。
设置优先级,QoS, 依赖等一些进阶示例:
let backgroundOperation = NSOperation()
backgroundOperation.queuePriority = .Low
backgroundOperation.qualityOfService = .Background
let operationQueue = NSOperationQueue.mainQueue()
operationQueue.addOperation(backgroundOperation)
// dependence
let networkingOperation: NSOperation = ...
let resizingOperation: NSOperation = ...
resizingOperation.addDependency(networkingOperation)
let operationQueue = NSOperationQueue.mainQueue()
// 虽然resizing添加了network为依赖,但是还是需要全部加到队列里
// 不要以为加了尾部operation就能把依赖全加进去
operationQueue.addOperations([networkingOperation, resizingOperation], waitUntilFinished: false)
Grand Central Dispatch
可以认为GCD是更底层的Operation,它甚至直接嵌入了操作系统,能被任何代码执行而且非常高效。调用过程也与Operation差不多:
- 表示一个task
- 加入一个queue
- GCD Queue也被表示成了dispatch queue
- a lightweight opaque pseudo-object consisting essentially of
a list of functions to be executed.
- 如果自定义这个queue,它默认状态下是
serial queue
let MANDELBROT_STEPS = 100
var bitmapContext: CGContext!
let draw_queue = DispatchQueue(label: "com.neuburg.mandeldraw")
// 改造一个返回前述跨线程变量的方法
func makeBitmapContext(size:CGSize) -> CGContext {
// ... as before ...
let context = CGContext(data: nil,
width: Int(size.width), height: Int(size.height),
bitsPerComponent: 8, bytesPerRow: bitmapBytesPerRow,
space: colorSpace, bitmapInfo: prem)
return context!
}
// 相应方法增加这个context参数,而不是从环境里取
func draw(center:CGPoint, bounds:CGRect, zoom:CGFloat, context:CGContext) {
// ... as before, but we refer to local context, not self.bitmapContext
}
// 剩下的,一个block搞定:
// UI触发的事件
func drawThatPuppy () {
let center = self.bounds.center
let bounds = self.bounds
self.draw_queue.async {
// 下面两行代码虽然用到了self,但是它们没有改变任何属性,是线程安全的
let bitmap = self.makeBitmapContext(size: bounds.size)
self.draw(center: center, bounds: bounds, zoom: 1, context: bitmap)
DispatchQueue.main.async {
self.bitmapContext = bitmap
self.setNeedsDisplay()
}
}
}
可以看到,相比Operation把代码结构都改了,GCD几乎只是包了一层block,代码变动非常少。(唯一的发动就是把所有执行代码的变量都需要通过参数机制传进去)。
同时, center, bounds等参数,直接从环境里取,这是block机制带来的便利;同样的机制也被用在了线程共享的变量传回主线程时,因为对第二层block而言,第一层block就是它的higher surrounding scope,是能看到它的bitmap变量的。 -> 我们并没有从头到尾retrive一个self.bitmap变量,也就不存在data sharing。
不像Operation把耗时操作写在别处,GCD的方式易读性更高。
除了有.async(execute:),还有asyncAfter(deadline:execute:)和sync(execute:),望文生义,就不多介绍了。
Dispatch Groups
group提供了监听(wait)一组后台线程全部执行结束的功能:
let outerQueue = DispatchQueue(label: "outer")
let innerQueue = DispatchQueue(label: "inner")
let group = DispatchGroup()
outerQueue.async {
let series = "123456789"
for c in series {
group.enter() // flag 1
innerQueue.asyncAfter(
deadline:.now() + .milliseconds(Int.random(in: 1...1000))) {
print(c, terminator:"")
group.leave() // flag 2
}
group.wait() // 一旦加了这句话,这9个线程就变成线性的了,注释掉,就是9个线程随机先后执行
}
// 可见这个notify等同于wait_all
// 当enter次数与leave次数一致时触发
group.notify(queue: DispatchQueue.main) {
print("\ndone")
}
}
One-Time Execution
Objective-C中实现单例的dispatch_once其实就是GCD的内容,而在Swift中这个方法就没有了,也没用GCD去实现了:
let globalOnce : Void = {
print("once in a lifetime") // once, at most
}()
这个print只会打印一次。而如果是用在对象中,可以声明为lazy:
class ViewController: UIViewController {
private lazy var instanceOnce : Void = {
print("once in an instance") // once per instance, at most
}()
// ... }
instanceOnce这个变量也只会初始化一次。
Bonus
// 并发
let queue = DispatchQueue(label: "queue", attributes: .concurrent)
// 条件, check the queue
dispatchPrecondition(condition: .onQueue(self.draw_queue))
App Backgrounding
- 应用进入后台时,iOS系统会给应用
小于5秒的时间来结束当前的任务
- 可以用
UIApplication.shared.beginBackgroundTask(expirationHandler:)来申请更长的时间(不超过30秒),返回一个identifier
expirationHandler是一个超时还没处理完的话,系统会调的方法,
- 任务执行完后需要调用
UIApplication.shared.endBackgroundTask(_:)方法来结束后台时间的申请
expirationHandler里同样需要显式endBackgroundTask- 所以正常方法体和超时方法体都会有endBackgroundTask的调用
把这个特性直接封装到一个operation里去:
class BackgroundTaskOperation: Operation {
var whatToDo : (() -> ())?
var cleanup : (() -> ())?
override func main() {
guard !self.isCancelled else { return }
var bti : UIBackgroundTaskIdentifier = .invalid
bti = UIApplication.shared.beginBackgroundTask {
self.cleanup?()
self.cancel()
UIApplication.shared.endBackgroundTask(bti) // cancellation
}
guard bti != .invalid else { return }
whatToDo?()
guard !self.isCancelled else { return }
UIApplication.shared.endBackgroundTask(bti) // completion
}
}
// 调用
let task = BackgroundTaskOperation()
task.whatToDo = {
...
}
myQueue.addOperation(task)
这样,
- 正常情况下会执行
whatToDo()
- 如果应用被挂到后台,因为注册过后台任务,有小于30秒的时间跑完任务
- 如果顺利跑完,你把应用切到前台,会发现UI已经更新了
- 超时也没跑完,就会进入超时的block里去取消任务了,UI上也得不到结果
最后,要知道所谓的申请时长,并不是在didEnterBackground之类的方法里去做的,而是做任务的时候就直接注册了,是不是很麻烦?
Background Processing
相比向系统申请少得可怜的后台挂起时间,iOS 从13开始引入了后台任务机制,方便你执行一些用户不需要感知的任务,比如下载,或数据清理:
- 路径:target > Signing & Capabilities > Background processing
- use
Background Task framework, need to import BackgroundTasks
- Info.plist > add "Permitted background task schedule identifiers" key (
BTTaskSchedulerPermittedIdentifiers), 任意标识字符串,比如反域名
- 在
appDelegate里面去实现需要后台执行的方法
涉及到两个类:
BGProcessingTaskRequest
- 在
didEnterBackground方法里调用
- 需要match plist.info里的id
- 注册是否通电/有网/延迟执行(ExternalPower / Network / earliestBeginDate)
BGTaskScheduler
application(_:didFinishLaunchingWithOptions:)里执行register(forTaskWithIdentifier:using:launchHandler:)方法
- id: matching plist.info
- using: dispatch queue
- handler:
BGTask object
- 在
BGTask的超时方法里,和正常执行的代码里,均需调用setTaskCompleted(_:bool)方法
let taskid = "com.neuburg.matt.lengthy"
func application(_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions:
[UIApplication.LaunchOptionsKey : Any]?) -> Bool {
}
// let v = MyView()
let ok = BGTaskScheduler.shared.register(
forTaskWithIdentifier: taskid,
using: DispatchQueue.global(qos: .background)) { task in
task.expirationHandler = {
task.setTaskCompleted(success: false)
}
//... my task logic
task.setTaskCompleted(success: true)
}
// might check `ok` here
return true
}
func applicationDidEnterBackground(_ application: UIApplication) {
// might check to see whether it's time to submit this request
let req = BGProcessingTaskRequest(identifier: self.taskid)
try? BGTaskScheduler.shared.submit(req)
}
Debug
- 打满print和断点
- 设备上,把应用送到后台再拉到前台
- Xcode上暂停app
(lldb) e -l objc -- (void)[[BGTaskScheduler sharedScheduler] _simulateLaunchForTaskWithIdentifier:@"my_id"] 模拟launching
(lldb) e -l objc -- (void)[[BGTaskScheduler sharedScheduler] _simulateExpirationForTaskWithIdentifier:@"my_id"] 模拟超时
- 控制台输入
continue, 运行task function
- 当
task.setTaskComplete(success: true) 被调用,控制台输出:“Marking simulated task complete,”
BGAppRefreshTaskRequest
not mentioned