cs193p_2021_笔记[1]
2020年看了一遍,后来学深度学习去了,然后发现2021也出来了,仍然是视频授课(对我们没区别),看完后整理了两年课程的笔记。
本文涉及内容:struct, enum, optional, protocol, viewbuilder, shape
struct and class
拥有差不多的结构
- stored vars
- computed vars
- constant lets
- functions
- initializers
differents: struct | class -------|------ Value type | Reference type Copied when passed or assigned | Passed around via pointers Copy on write | Automatically reference counted Functional programming | Object-oriented programming No inheritance | Inheritance (single) “Free”(缺省) init initializes ALL vars | “Free” init initializes NO vars Mutability must be explicitly stated | Always mutable (即使用let, 只表示不会改变指针) Your “go to” data structure | Used in specific circumstances Everything you’ve seen so far is a struct (except View which is a protocol) | The ViewModel in MVVM is always a class (also, UIKit (old style iOS) is class-based)
泛型,函数类型,闭包
- 允许未知类型,但swift是强类型,所以用类型占位符,用作参数时参考.net的泛型
- 函数也是一种类型,可以当作变量,参数,出现在变量,参数的位置
- in-line风格的函数叫
closure(闭包)
enum
- 枚举是值类型
- 枚举的每个state都可以有
associated data(等于是把每个state看成一个class/struct,associated data就可以理解为属性)
enum FastFoodMenuItem {
case hamburger(numberOfPatties: Int)
case fries(size: FryOrderSize)
case drink(String, ounces: Int) // the unnamed String is the brand, e.g. “Coke”
case cookie }
enum FryOrderSize {
case large
case small }
let menuItem: FastFoodMenuItem = FastFoodMenuItem.hamburger(patties: 2)
var otherItem: FastFoodMenuItem = FastFoodMenuItem.cookie
var yetAnotherItem = .cookie // Swift can’t figure this out
- FryOrderSize同时又是一个枚举
- 状态drink拥有两个“属性”,而且其中一个还未命名
break and fall through/defaults
var menuItem = FastFoodMenuItem.cookie
switch menuItem {
case .hamburger: break // break
case .fries: print(“fries”)
default: print(“other”) // default
}
- 如果把drink写上,但没有方法体,则叫
fall through,只会往后面一个state fall through - 如果漏写了drink,则会匹配到default项(cookie同理)
with associated data
var menuItem = FastFoodMenuItem.drink(“Coke”, ounces: 32)
switch menuItem {
case .hamburger(let pattyCount): print(“a burger with \(pattyCount) patties!”)
case .fries(let size): print(“a \(size) order of fries!”)
case .drink(let brand, let ounces): print(“a \(ounces)oz \(brand)”)
case .cookie: print(“a cookie!”)
}
可以拥有方法
这就可以扩展出computed vars
enum FastFoodMenuItem { ...
func isIncludedInSpecialOrder(number: Int) -> Bool {
switch self {
case .hamburger(let pattyCount): return pattyCount == number
case .fries, .cookie: return true // a drink and cookie in every special order
case .drink(_, let ounces): return ounces == 16 // & 16oz drink of any kind
} }
}
Iterable
conform CaseIterable协议就能被遍历,因为增加了一个allCases的静态变量:
enum TeslaModel: CaseIterable {
case X
case S
case Three
case Y
}
for model in TeslaModel.allCases {
reportSalesNumbers(for: model)
}
func reportSalesNumbers(for model: TeslaModel) {
switch model { ... }
}
SwiftUI实例, LazyVGrid中:
struct GridItem {
...
enum Size {
case adaptive(minimum: CGFloat, maximum: CGFloat = .infinity)
case fixed(CGFloat)
case flexible(minimum: CGFloat = 10, maximum: CGFloat = .infinity)
}
}
associated data还能带默认值- 核心作用是告诉系统griditem的size是采用哪种方案(枚举),顺便设置了这种方案下的参数。所以这种场景在swift下完全可以用枚举做到
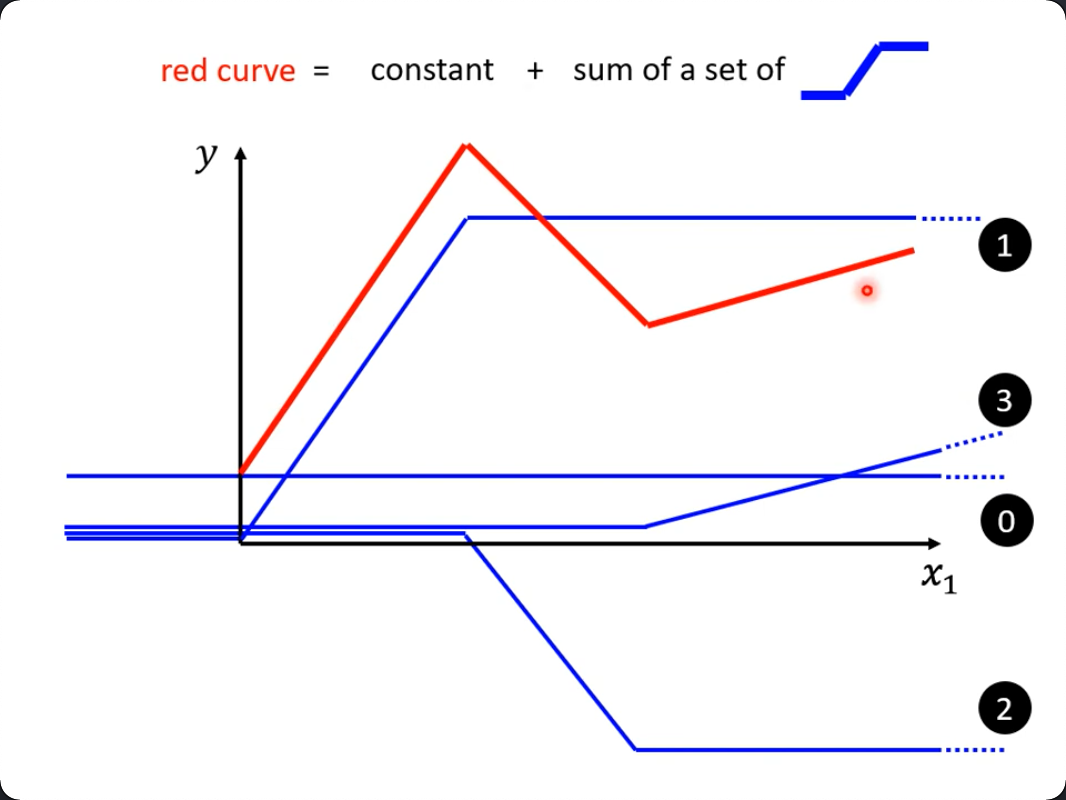
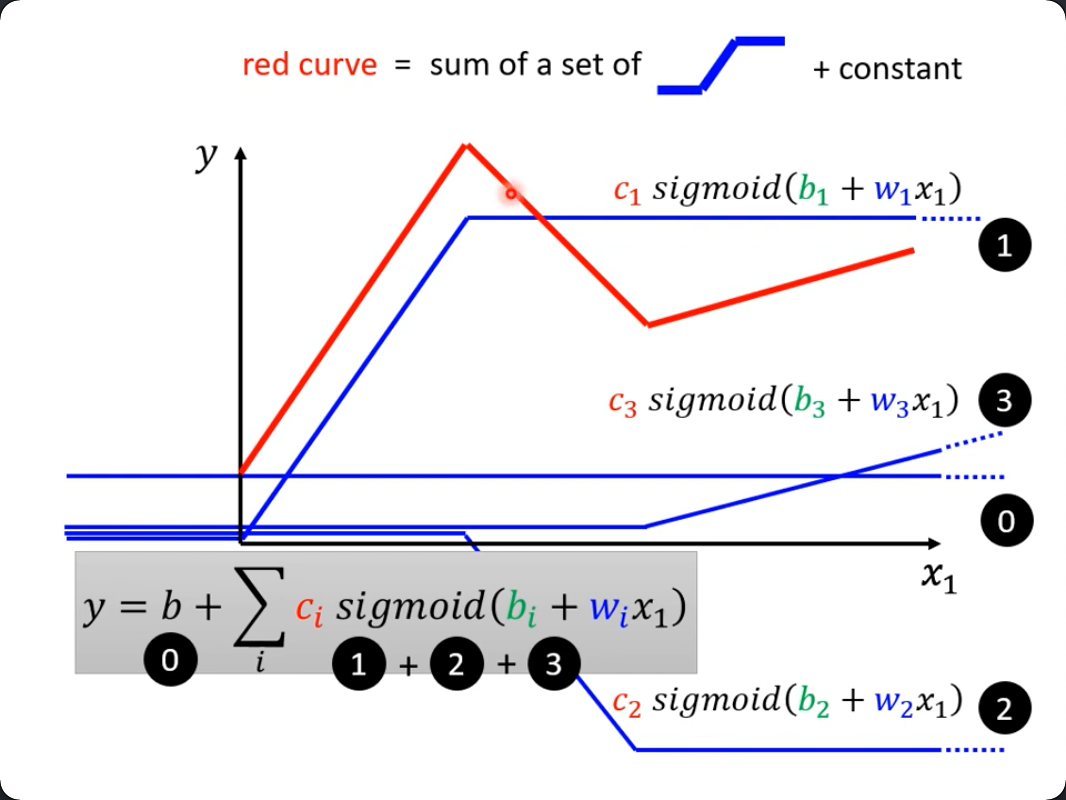
Optionals
可靠类型其实就是一个Enum
enum Optional<T> { // a generic type, like Array<Element> or MemoryGame<CardContent>
case none
case some(T) // the some case has associated value of type T }
它只有两个状态,要么是none,要么就是is set的状态,具体的值其实是绑定到了associate data里去了
所以你现在知道了有一种取法其实就是从some里面来取了。
语法糖
var hello: String?
var hello: String? = “hello”
var hello: String? = nil
// 其实是:
var hello: Optional<String> = .none
var hello: Optional<String> = .some(“hello”)
var hello: Optional<String> = .none
使用:
let hello: String? = ...
print(hello!)
// 其实是:
switch hello {
case .none: // raise an exception (crash)
case .some(let data): print(data)
}
if let safehello = hello {
print(safehello)
} else {
// do something else
}
// 其实是:
switch hello {
case .none: { // do something else }
case .some(let data): print(data)
}
// 还有一种:
let x: String? = ...
let y = x ?? “foo”
// 其实是:
switch x {
case .none: y = “foo”
case .some(let data): y = data
}
- 所以用
!来解包是会报错的原理在此 guard的原理同样是switch- 默认值的原理你应该也能猜到了
- 三个语法糖,对应的底层就是一句switch,其实就是
.none时的三种处理方案
当然,还可以chain起来
let x: String? = ...
let y = x?foo()?bar?.z
// 尝试还原一下:
switch x {
case .none: y = nil
case .some(let xval)::
switch xval.foo() {
case .none: y = nil
case .some(let xfooval):
switch xfooval.bar {
case .none: y = nil
case .some(let xfbarval):
y = xfbarval.z
}
}
}
记住每一个句号对应一个switch,然后在.none的状态下安全退出就是?的用法了。
@ViewBuilder
- 任意
func或只读的计算属性都可以标识为@ViewBuilder,一旦标识,它里面的内容将会被解析为a list of Views(也仅仅是这个,最多再加上if-else来选择是“哪些view”,不能再定义变量和写其它代码了)- 一个典型例子就是View里面扣出来的代码(比如子view)做成方法,这个方法是需要加上@ViewBuilder的
- 或者改语法
- 或者只有一个View,就不会产生语法歧义,也是可以不加@ViewBuilder的
- 所以不需要return,而如果你不打标,也是可以通过return来构建view的
- 但是就不支持默认返回list或通过if-else返view list的语法了
@ViewBuilder也可以标识为方法的参数,表示需要接受一个返回views的函数
init(items: [Item], @ViewBuilder content: @escaping (Item) -> ItemView) {...}
同时也注意一下@escaping,凡是函数返回后才可能被调用的闭包(逃逸闭包)就需要,而我们的view是在需要的时候才创建,或反复移除并重建(重绘)的,显然符合逃逸闭包的特征。
viewbuilder支持的控制流程代码指的是
if-else和ForEach, 所以for...in...是不行的。
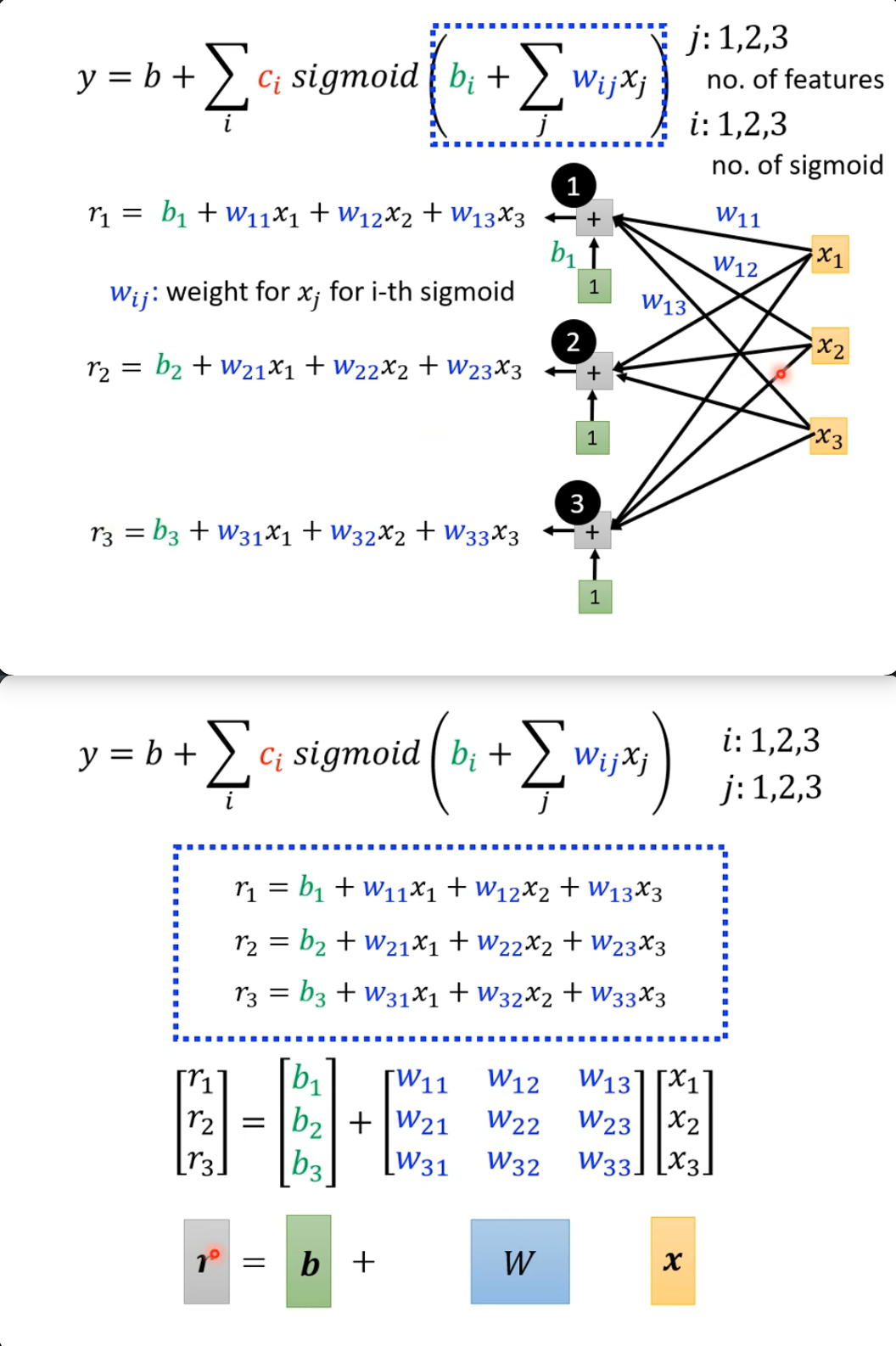
Protocol
接口,协议,约束... 使用场景:
- 用作类型(Type):
- func travelAround(using moveable: Moveable)
- let foo = [Moveable]
- 用作接口:
- struct cardView: View
- class myGame: ObservableObject
- behaviors: Identifiable, Hashable, ... Animatable
- 用作约束:
struct Game
whereContent: Equtable // 类 extension ArraywhereElement: Hashable {...} // 扩展 init(data: Data)whereData: Collection, Data.Element: Identifiable // 方法 - OC里的delegate
- code sharing (by
extension)extensionto a protocol- this is how Views get forecolor, font and all their other modifiers
- also `firstIndex(where:) get implemented
- an
extensioncan add default implementation for a func or a var- that's how
objectWillChangecomes from
- that's how
extension可以作用到所有服从同一协议的对象- func filter(_ isIncluded: (Element) -> Bool) -> Array
- 只为
Sequenceprotocol写了一份filter的扩展代码,但能作用于Array, Range, String, Dictionary - 等一切conform to the
Sequenceprotocol的类
- func filter(_ isIncluded: (Element) -> Bool) -> Array
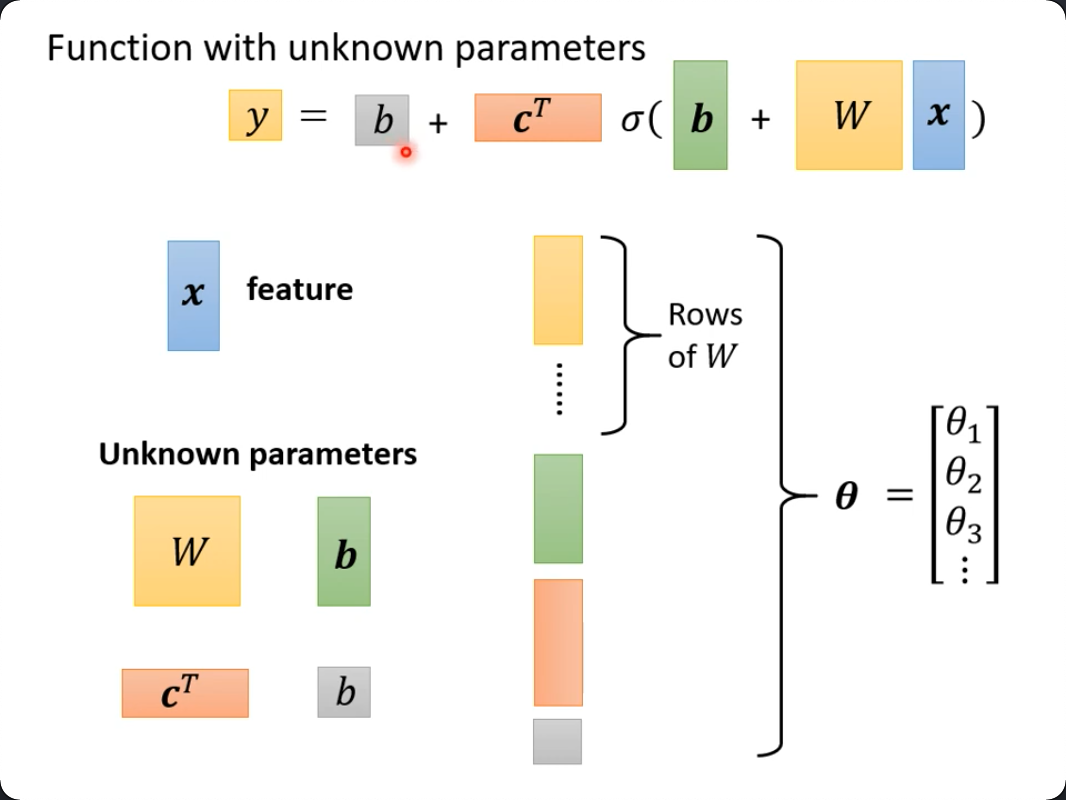
SwiftUI的View protocol非常简单,conform 一个返回some view的body方法就行了,但是又为它写了无数extension,比如foregroundColor, padding, etc. 示意图:
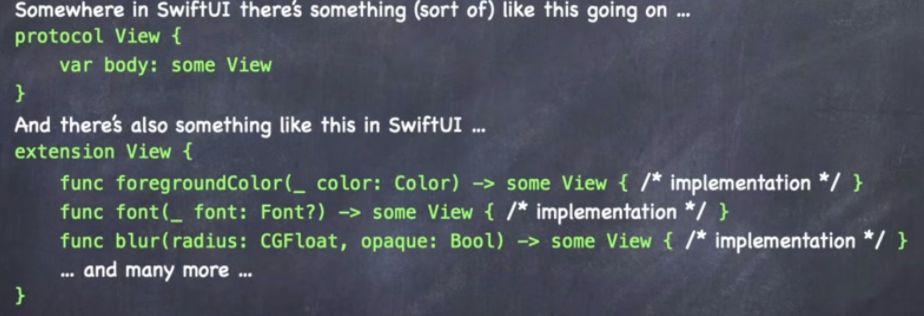
Generics(泛型)
举例:
protocol Identifiable {
associatedtype ID: Hashable
var id: ID { get }
}
- 不像struct,protocol并不是用
Identifiable<ID>来表示泛型,而是在作用域内定义 - 上例中,ID既定义了类别别名,还规范了约束
- 所以你Identifiable的类, 是需要有一个Hashable的ID的
- 而Hashable的对象,又是需要Equatable的(因为hash会碰撞出相同的结果,需要提供检查相等的方法)
- ->
protocol inheritancee
Shape
- Shape is a
protocolthat inherits fromView. - In other words, all Shapes are also Views.
- Examples of Shapes already in SwiftUI: RoundedRectangle, Circle, Capsule, etc.
- by default, Shapes draw themselfs by
fillingwith the current foreground color.
func fill<S>(_ whatToFillWith: S) -> some view where S: ShapeStyle
ShapeStyle protocol turns a Shape into a View: Color, ImagePaint, AngularGradinet, LinearGradient
自定义shape最好用path(系统的已经通过extension实现好了view的body):
func path(in rect: CGRect) -> Path {
return a Path
}