an agent receives information about its environment and learns to choose actions that will maximize some reward.
可以用训练狗来理解
工业界的应用除了游戏就是机器人了
Data preprocessing
vectorization
normalization (small, homogenous)
handling missing values
除非0有特别的含义,不然一般可以对缺失值补0
你不能保证测试集没有缺失值,如果训练集没看到过缺失值,那么将不会学到忽略缺失值
复制一些训练数据并且随机drop掉一些特征
feature extraction
making a problem easier by expressing it in a simpler way. It usually requires understanding the problem in depth.
Before deep learning, feature engineering used to be critical, because classical shallow algorithms didn’t have hypothesis spaces rich enough to learn useful features by themselves. (又见假设空间)
但是好的特征仍然能让你在处理问题上更优雅、更省资源,也能减小对数据集规模的依赖。
Overfitting and underfitting
Machine learning is the tension between optimization and generalization.
given two explanations for something, the explanation most likely to be correct is the simplest one—the one that makes fewer assumptions.
即为传说中如无必要,勿增实体的奥卡姆剃刀原理,这是在艺术创作领域的翻译,我们这里还是直译的好,即能解释一件事的各种理解中,越简单的,假设条件越少的,往往是最正确的,引申到机器学习,就是如何定义一个simple model
A simple model in this context is:
a model where the distribution of parameter values has less entropy
or a model with fewer parameters
实操就是,就是迫使选择那些值比较小的weights,which makes the distribution of weight values more regular. This is called weight regularization。这个解释是我目前看到的最regularization这个名字最好的解释,“正则化”三个字都认识,根本没人知道这三个字是什么意思,翻译了跟没番一样,而使分布更“常规化,正规化”,好像更有解释性。
L1 regularization—The cost added is proportional to the absolute value of the weight coefficients (the L1 norm of the weights).
L2 regularization—The cost added is proportional to the square of the value of the weight coefficients (the L2 norm of the weights).
L2 regularization is also called weight decayin the context of neural networks. Don’t let the different name confuse you: weight decay is mathematically the same as L2 regularization.
只需要在训练时添加正则化
Dropout
randomly dropping out (setting to zero) a number of output features of the layer during training.
Layers, which are combined into a network (or model)
layers: 常见的比如卷积层,池化层,全连接层等
models: layers构成的网络,或多个layers构成的模块(用模块组成网络)
Two-branch networks
Multihead networks
Inception blocks, residual blocks etc.
The topology of a network defines a hypothesis space
本书反复强调的就是这个hypothesis space,一定要理解这个思维:
By choosing a network topology, you constrain your space of possibilities (hypothesis space) to a specific series of tensor operations, mapping input data to output data.(network的选择约束了tensor变换的步骤)
At its core, it’s a different way to look at data—to represent or encode data.
简单回顾深度学习之于人工智能的历史,每本书都会写,但每本书里都有作者自己的侧重:
Artificial intelligence
Machine learning
Machine learning is tightly related to mathematical statistics, but it differs from statistics in several important ways.
machine learning tends to deal with large, complex datasets (such as a dataset of millions of images, each consisting of tens of thousands of pixels)
classical statistical analysis such as Bayesian analysis would be impractical(不切实际的).
It’s a hands-on discipline in which ideas are proven empirically more often than theoretically.(工程/实践大于理论)
是一种meaningfully transform data
Machine-learning models are all about finding appropriate representations for their input data—transformations of the data that make it more amenable to the task at hand, such as a classification task.
寻找更有代表性的representation, 通过:(coordinate change, linear projections, tranlsations, nonlinear operations)
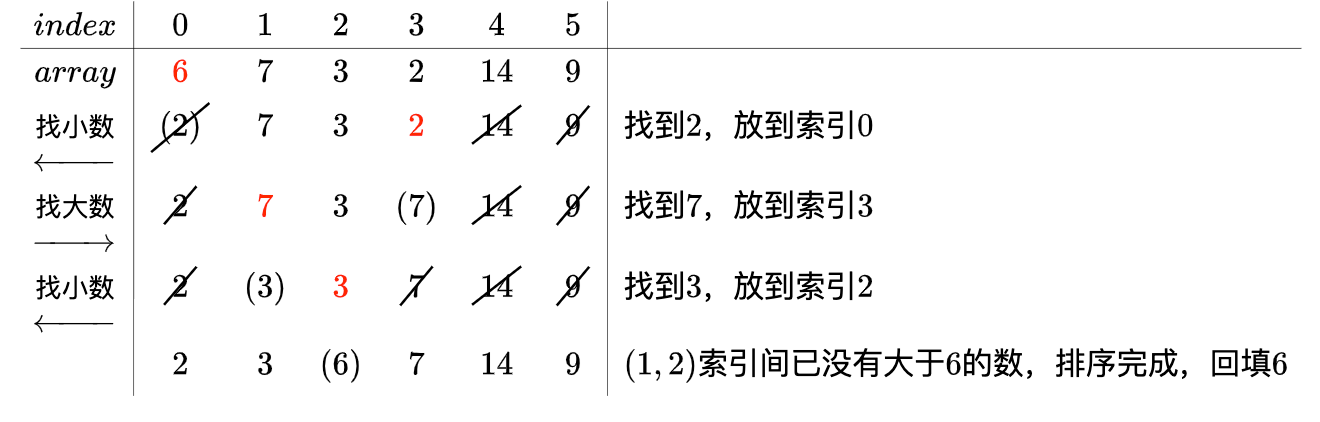
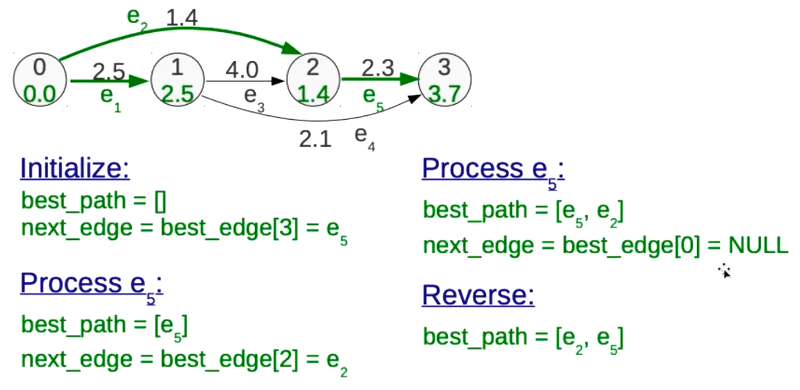
在实现每一轮的遍历数字较大的那个子节点并交换数字的过程中,我之前用的是递归,在小数据量顺利通过,但上万条数据时碰到了RecursionError: maximum recursion depth exceeded in comparison, 查询本机迭代大小设置为1000,但设到几十万就不起作用了(虽然不报错),于是改成了while循环,代码几乎没变,但是秒过了。
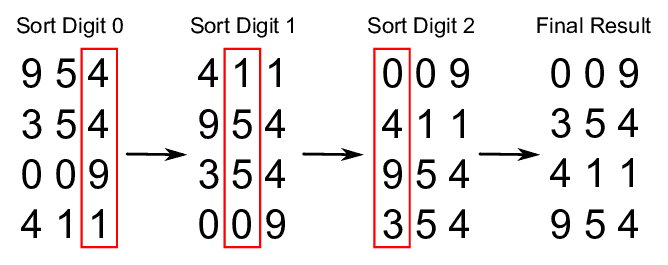
if__name__=="__main__":importnumpyasnpimporttimenp.random.seed(7)length=20000arr=list(np.random.randint(0,length*50,size=(length,)))print(f'{length} random integers sort comparation:')foriinrange(5):print(f'-------------round {i+1}------------')# insert is too slow# or my implementation is not so good# start = time.time()# s1 = insert_sort(arr)# print(f"insert_sort\t {time.time()-start:.5f} seconds")start=time.time()s2=quick_sort(arr.copy())print(f"quick_sort\t{time.time()-start:.5f} seconds")start=time.time()s3=shell_sort(arr.copy())print(f"shell_sort\t{time.time()-start:.5f} seconds")start=time.time()s4=heap_sort(arr.copy())print(f"heap_sort\t{time.time()-start:.5f} seconds")start=time.time()s5=merge_sort(arr.copy())print(f"merge_sort\t{time.time()-start:.5f} seconds")start=time.time()s6=radix_sort(arr.copy())print(f"radix_sort\t{time.time()-start:.5f} seconds")print(f"first 10 numbers:\n{s2[:10]}\n{s3[:10]}\n{s4[:10]}\n{s5[:10]}\n{s6[:10]}")
match p = (n) -[*1..2] -> (m) where n.name='特朗普' return p
match p = ({name: '特朗普'}) - [*1..2] -> () return p # 简化
match p = (n)-[m]->(q) where m.name = '丈夫' return n,q skip 10 limit 5
match p = (n)-[:丈夫]->(q) return n,q skip 10 limit 5 # 简化
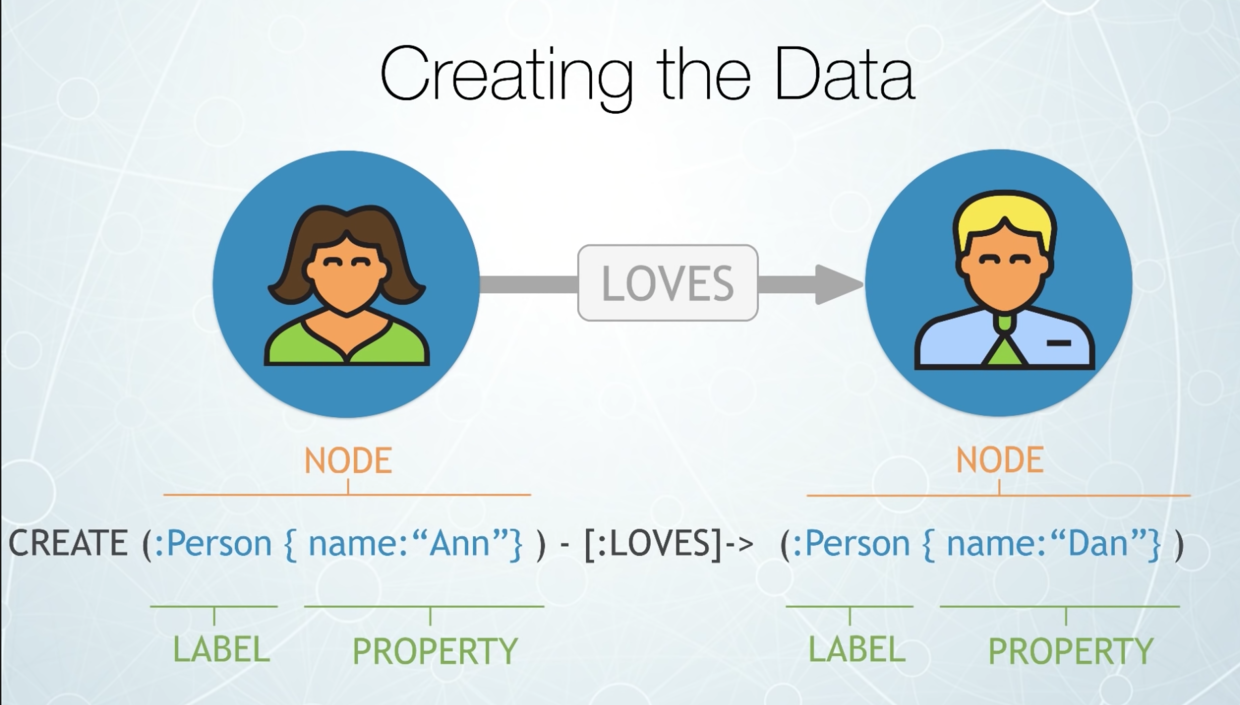
MATCH
(:Person {name: "张三"}) - [:LOVES] -> (p:Person)
RETURN
p
MATCH
(p1:Person) - [:LOVES] -> (p2:Person)
WHERE
p1.name = "张三"
SET
p2.age = 33 # set by property
# or
p2 += {age: 33, height: 180} # set by JSON
RETURN
p2
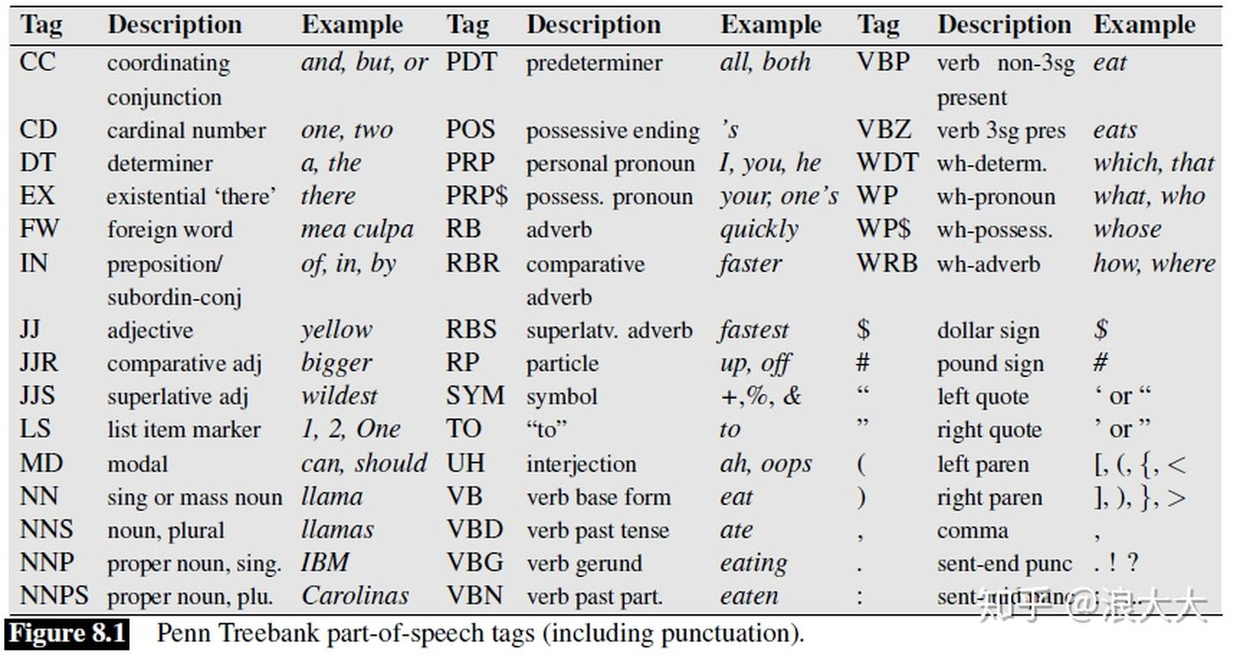
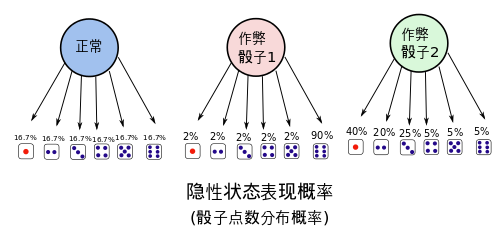
标记是一项消除歧义的任务;单词是模糊的,有不止一个可能的词性(歧义),我们的目标是为这种情况找到正确的标签。例如,book可以是动词(book that flight),也可以是名词(hand me that book)。That可以是一个限定词(Does that flight serve dinner),也可以是一个补语连词(I thought that your flight was earlier)。后置标记的目标是解决这些分辨率模糊,为上下文选择合适的标记
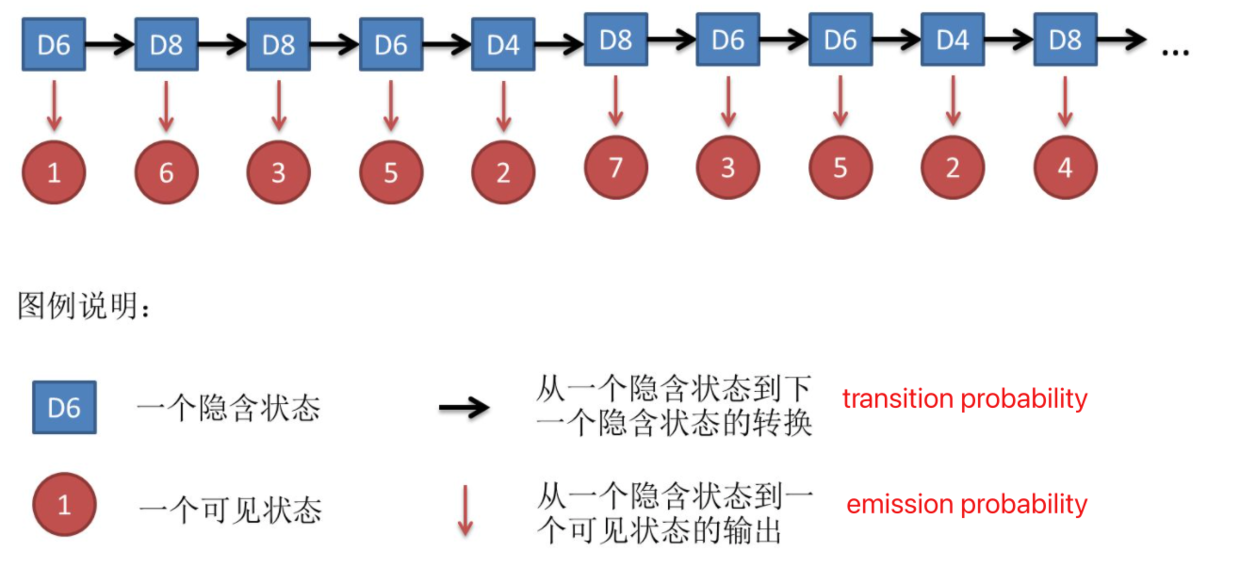
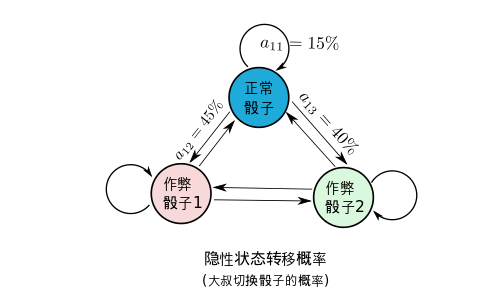
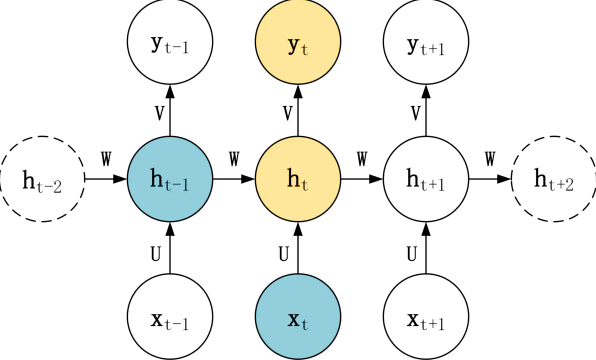
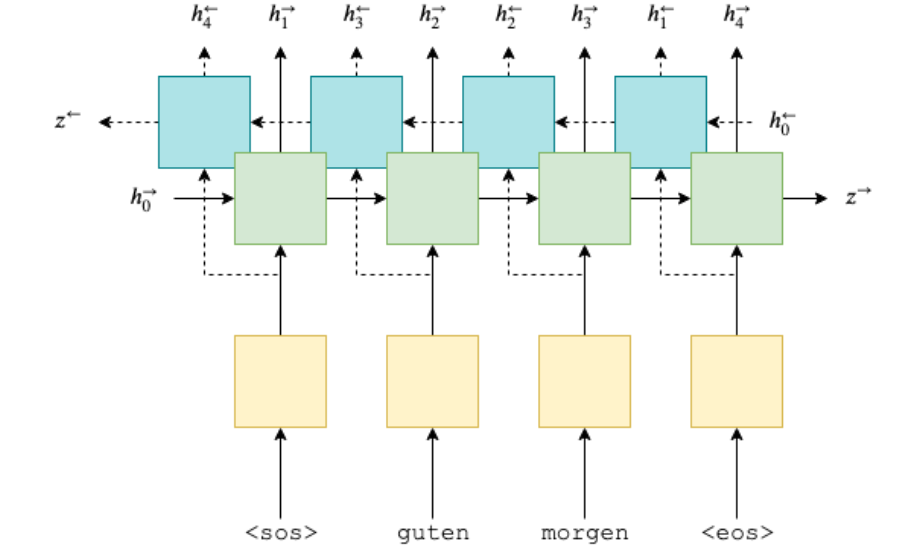
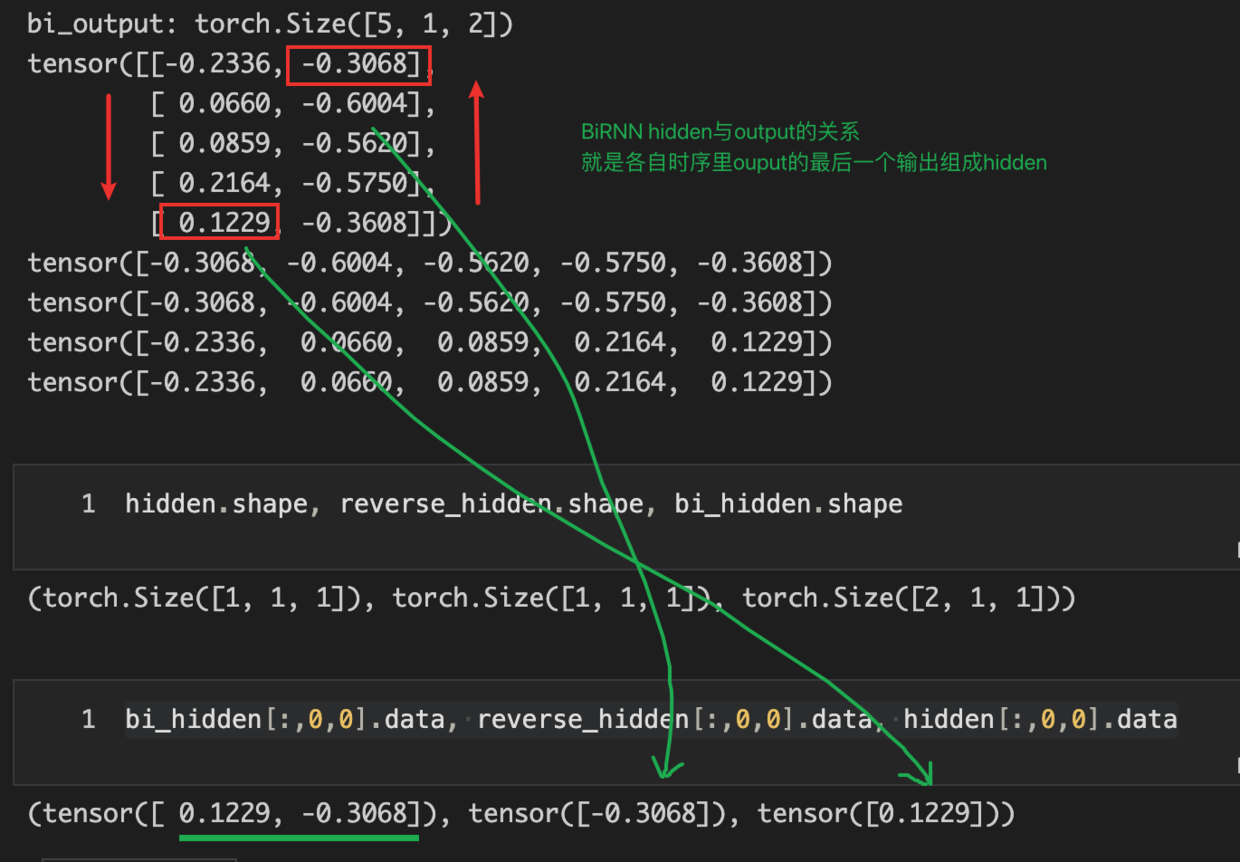
Sequence model
Sequence models are central to NLP: they are models where there is some sort of dependence through time between your inputs.
The classical example of a sequence model is the Hidden Markov Model for part-of-speech tagging. (词性标注)
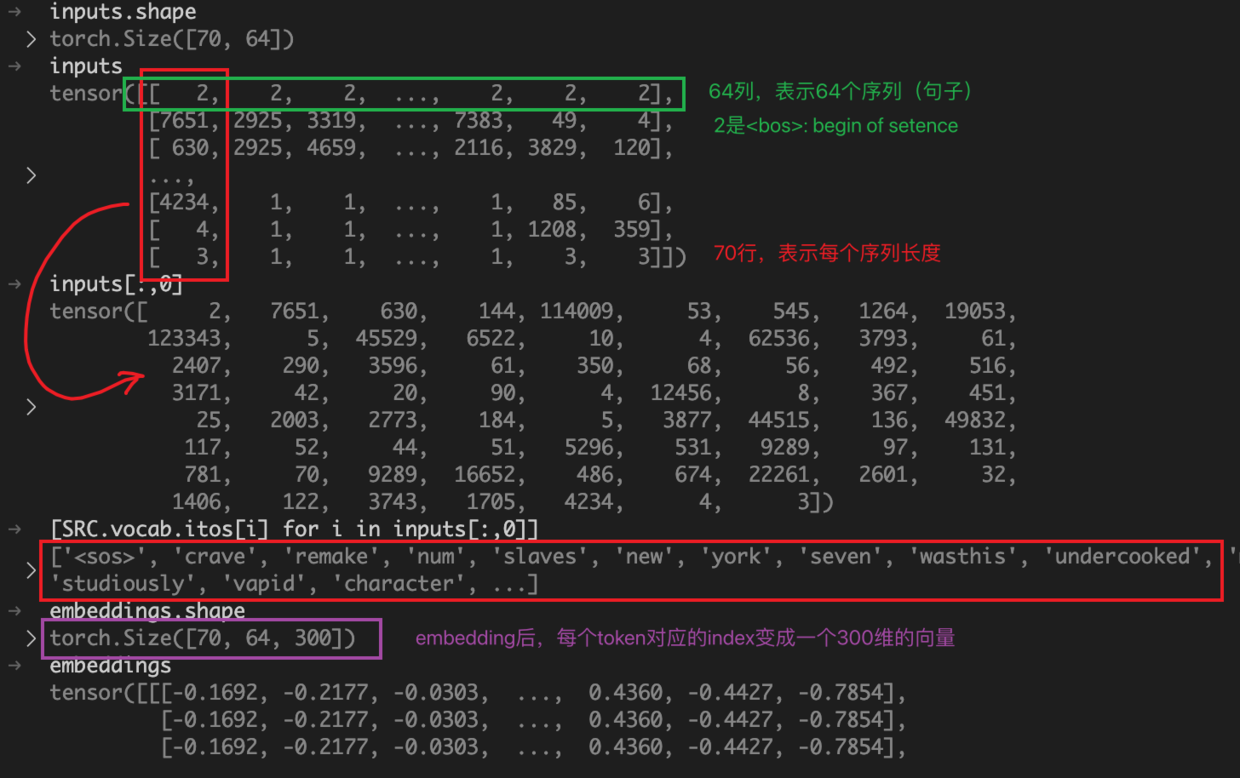
fromtorch.utils.dataimportTensorDatasetdefget_pseudo_labels(dataset,model,threshold=0.65):# This functions generates pseudo-labels of a dataset using given model.# It returns an instance of DatasetFolder containing images whose prediction confidences exceed a given threshold.# You are NOT allowed to use any models trained on external data for pseudo-labeling.device="cuda"iftorch.cuda.is_available()else"cpu"# Construct a data loader.data_loader=DataLoader(dataset,batch_size=batch_size,shuffle=False)# Make sure the model is in eval mode.model.eval()# Define softmax function.softmax=nn.Softmax(dim=-1)# Iterate over the dataset by batches.images=torch.Tensor([])targets=torch.Tensor([])forbatchintqdm(data_loader):img,_=batch# Forward the data# Using torch.no_grad() accelerates the forward process.withtorch.no_grad():logits=model(img.to(device))# Obtain the probability distributions by applying softmax on logits.probs=softmax(logits)# ---------- TODO ----------# 在这里根据阈值判断是否保留# Filter the data and construct a new dataset.foridx,probinenumerate(probs):c=torch.argmax(prob)ifprob[c]>threshold:torch.cat((images,img[idx]))# 用索引选出对应的图片torch.cat((targets,torch.tensor(c)))# 用最大值索引当classdataset=TensorDataset(images,targets)# 拼成tensor dataset# # Turn off the eval mode.model.train()returndataset
使用:
pseudo_set=get_pseudo_labels(unlabeled_set,model)# Construct a new dataset and a data loader for training.# This is used in semi-supervised learning only.concat_dataset=ConcatDataset([train_set,pseudo_set])# 拼接两个dataset(只要有感兴趣的两组数组即可)train_loader=DataLoader(concat_dataset,batch_size=batch_size,shuffle=True,num_workers=4,pin_memory=True)